

2025ISCC区域赛MISC
一、签个到吧
这道题球的,别看题目名字是“签到”,破事还挺多的。
二维码图片,又是猫脸变换,又是反色,还有图片旋转与图片合并……
一步步来吧……
(一)解压附件压缩包
还好,这个压缩包没有加密之类的,不然真的要脑大了……
1.解压压缩包后得到了:
图片1:flag_is_not_here.jpg,这是个二维码图片
![flag_is_not_here]()
破损压缩包:hint.zip
![破损压缩包hint.zip]()
2.尝试扫描二维码图片,发现一段文本:都说了这里没有flag。但是既然给了这张图片,那就肯定是有用的,我们先留着。
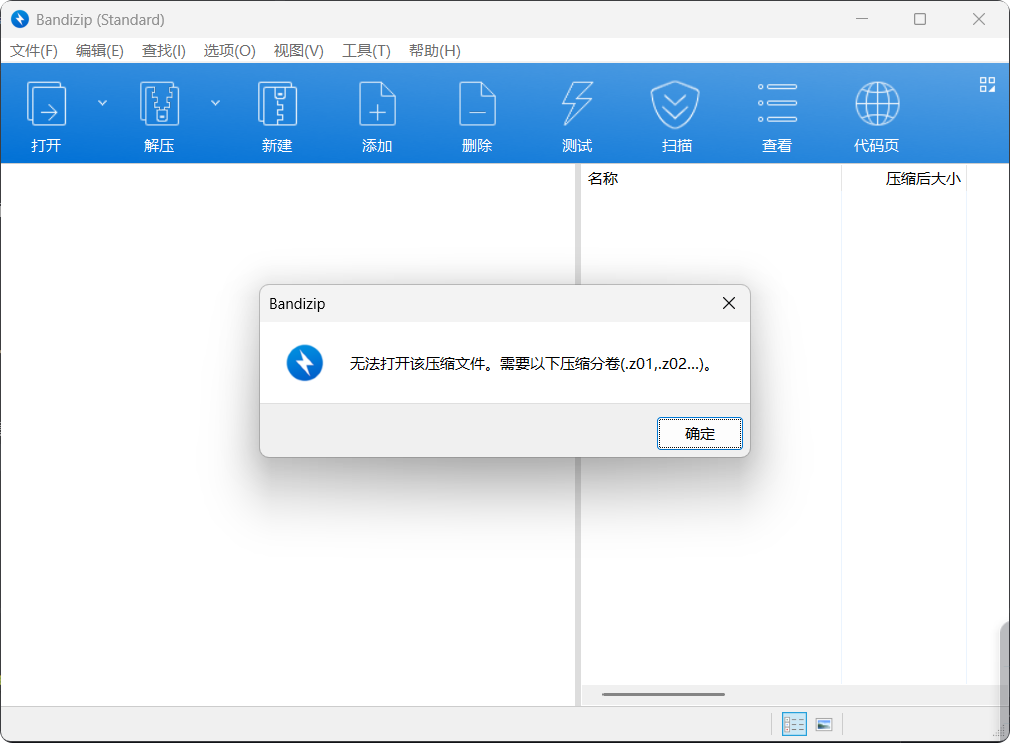
3.尝试打开压缩包,提示:无法打开压缩包,需要压缩分卷(.z01, .z02,……)
(二)修复压缩包
1.先用010editor看看压缩包的编码,发现不是zip的头,有问题,我们需要修复一下:将压缩包头修改为 50 4B 03 04
2.修复后,再打开压缩包,ok,成功打开,没有加密也成功解压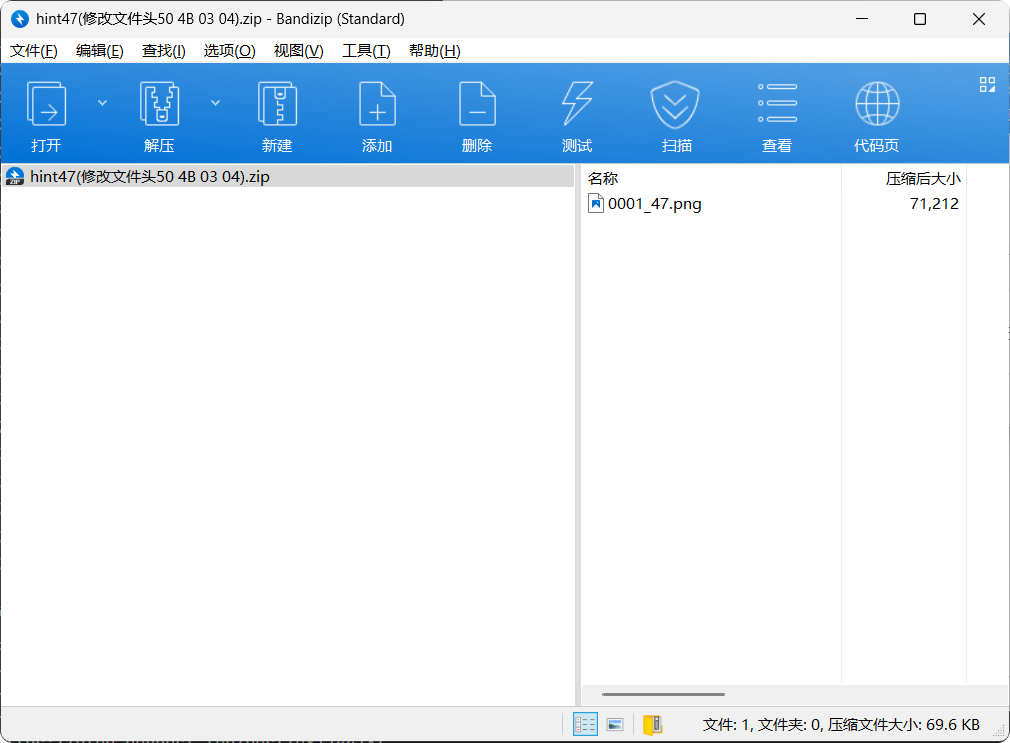
3.加压压缩包得到图片2:0001_47.png
(三)猫脸变换
1.用 StegSolve 打开 图片2
1 | # Stegsolve命令行启动 |
2.点击 File,导入图片2:0001_47.png
3.点击 Analyse -> Data Extract
Bit Plans 配置
Alpha: 0
Red: 0
Green: 0
Blue: 1
Extract By: Row
Bit Order: MSB First
Bit Plane Order: RGB
4.发现猫脸变换关键信息:ArnoldEn cryption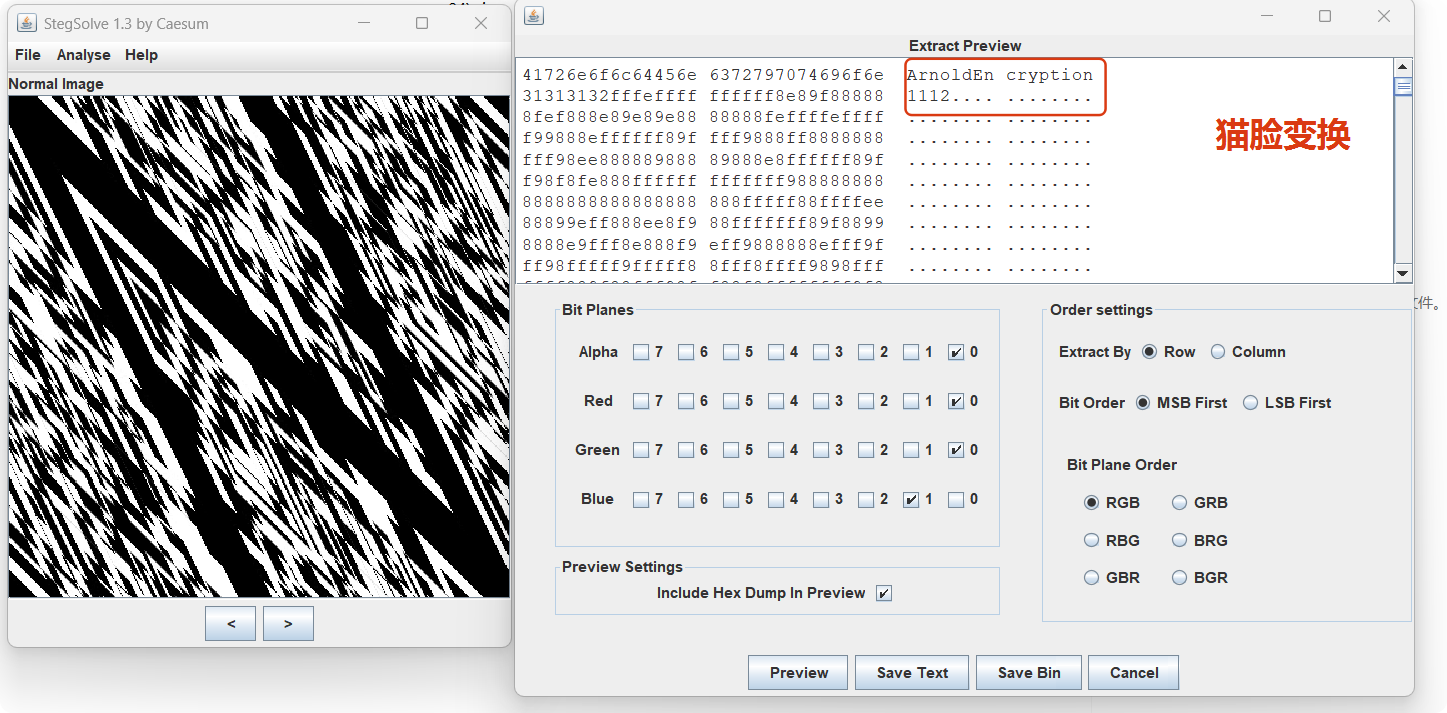
(五)猫脸变换Decode
猫脸变换的原理,这里我就不详细介绍了,感兴趣的请详细参考这篇文章
既然已经知道了加密方式,那就写个脚本Decode一下吧……
1 | # 导入必要的库 |
猫脸变换Decode后,得到图片3:flag_unscrambled.png
(六)图片反色
这里直接上工具随波逐流CTF,这个工具很强大,需要的友子可以自己下载使用……
对图片3进行反色处理,得到图片4:flag_modified.png

(七)图片旋转
这里图片逆时针旋转90°,得到图片5:flag_modified(逆时针旋转90度).png

(八)图片合并
最开始题目给的图片1:flag_is_not_here.jpg 就派上用途了,将处理后的0001_47.png也就是图片5:flag_modified(逆时针旋转90度).png与图片1:flag_is_not_here.jpg异或合并,得到最终的签到二维码
1.图片1:flag_is_not_here.jpg
2.图片5:flag_modified(逆时针旋转90度).png
3.最终的签到二维码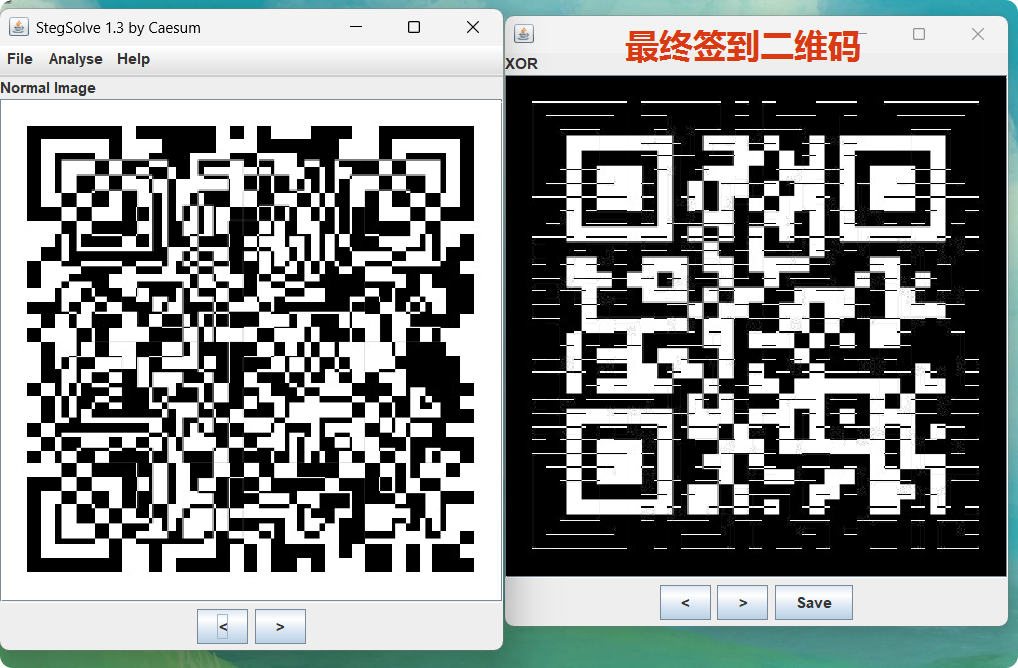
(九)扫描二维码得到Flag
这里还有点怪,有的手机可能扫不出来,,具体没试哪些可以哪些不可以。
反正我的手荣耀X50扫不出来,不管是微信、QQ还是浏览器的都不行。
于是我索性在电脑上用QQ图片自带的图片识别二维码功能,扫了一下,扫出来了!!!
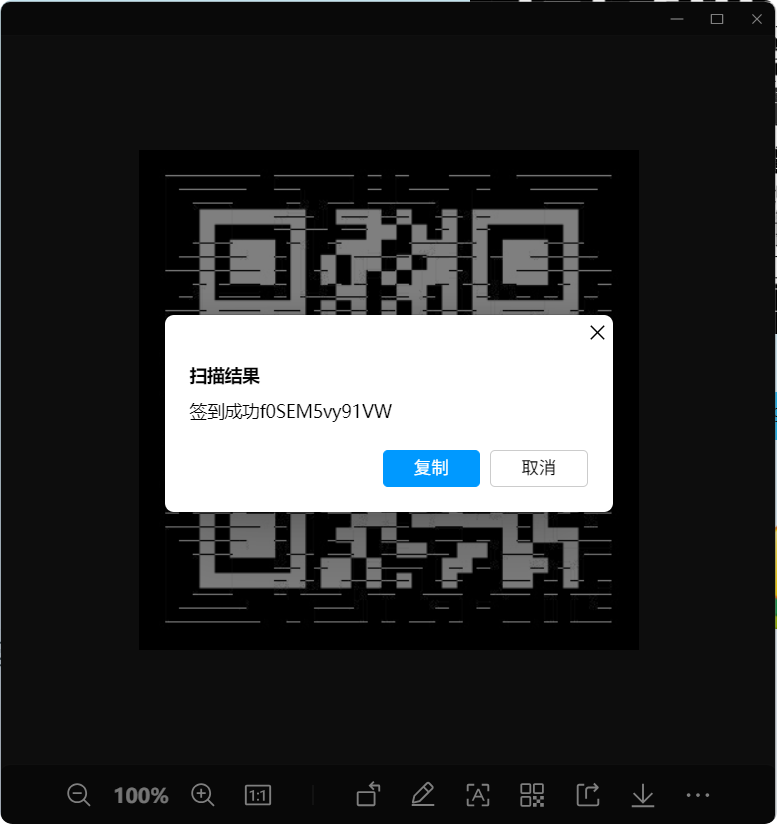
得到一段文本:签到成功f0SEM5vy91VW
Flag: ISCC{f0SEM5vy91VW}
二、睡美人
这道题,离奇,音频文件,曼彻斯顿编码
(一)分析图片
先看看给的压缩包1:attachment-29.zip,好家伙,一张12.9MB的图片 图1:Sleeping_Beauty_15.png,这张图片肯定有问题,应该是在图片的基础上将其他的图片或者文件给覆盖了,所以我们需要先将图片进行拆分
![压缩包1:attachment-29.zip]()
这里直接上工具foremast对图片进行分离,不出意外,得到了新的文件压缩包2:00026285.zip
![图1:Sleeping_Beauty_15.png]()
![压缩包2:00026285.zip]()


(二)破解加密压缩包
既然给我们的 压缩包1:attachment-29 没有加密,那么这个压缩包不出意外就是加密的了,我们直接打开看看,AES256加密
![加密压缩包:00026285.zip]()
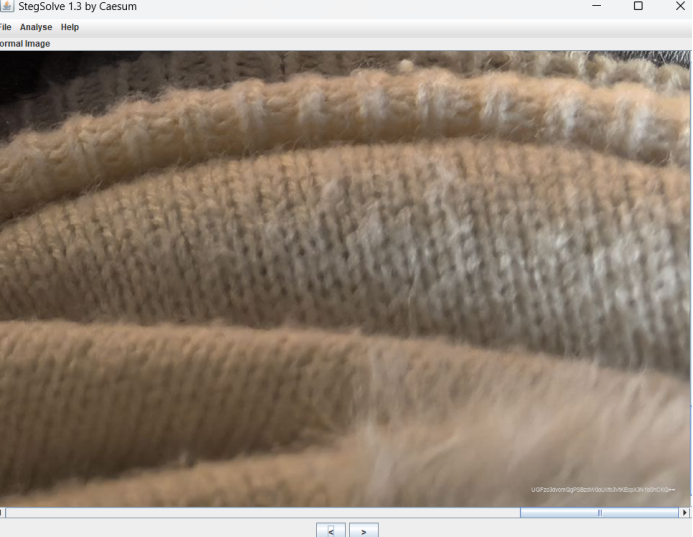
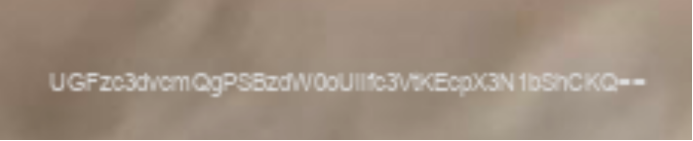
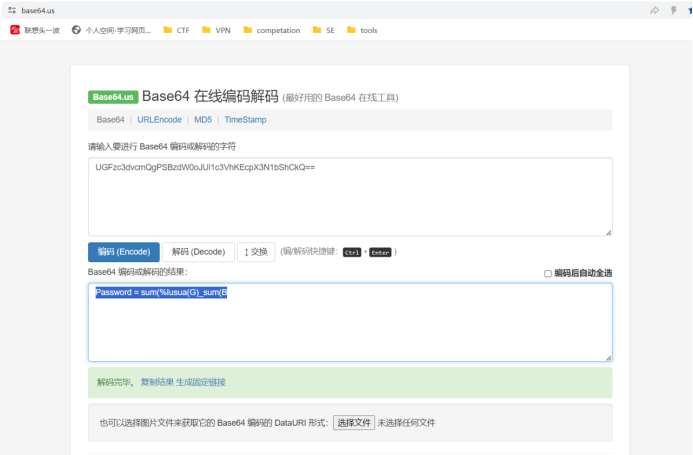
最开始的到的 图1:Sleeping_Beauty_15.png 是唯一的线索,那我们就还是从这张图片下手分析吧,本来准备用StegSolve分析的,但是发现没有什么信息,右下角有一个模糊胡的东西,放大一看果然有猫腻,藏这么小,得亏的窝的眼睛还可以,瞄到了这段 隐藏Base64编码字符串:UGFzc3dvcmQgPSBzdW0oJUl1c3VhKEcpX3N1bShCkQ==
![隐藏字符串]()
![隐藏字符串]()
随便找一个在线Base64解密的网站,解密一下,得到: Password = sum(%Iusua(G)_sum(B
![隐藏字符串Base64解密]()

(三)计算RGB加权值
1.分析Password = sum(%Iusua(G)_sum(B
- G、B:猜测一下应该是RGB三通道
- sum:求和
2.结合题目 “编织出红红红红红红绿绿绿蓝的梦幻篇章”
- 红红红红红红绿绿绿蓝,刚好10个字符,每个颜色重复出现的次数应该是就权重占比
- R【红】:6 —-> R:0.6
- G【绿】:3 —-> G:0.3
- B【蓝】:1 —-> B:0.1
3.构建脚本,计算RGB加权值
最终的到RGB加权值:加权颜色值: 1375729349.6
也就是得到的 Password = 1375729349.6
1 | from PIL import Image |
1.压缩包解密
使用刚才的到的 Password= 1375729349.6对 压缩包2:00026285.zip 进行解密,得到了一段音频文件:normal_speech_15.wav
(四)音频文件分析
1.音频文件分析,使用 Audacity 打开 音频文件:normal_speech_15.wav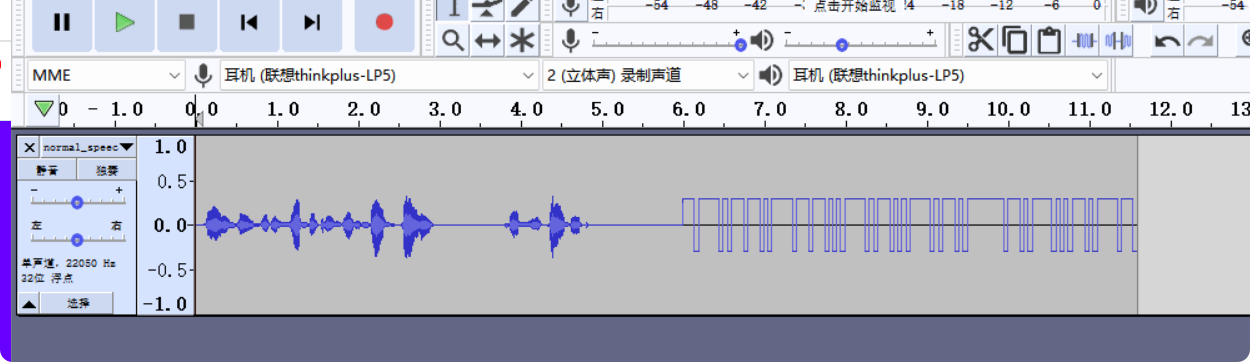
Audacity 免费音频工具自取
, 提取码:4mYV
2.发现从第6.0s开始,一直到第11.5s,这是一段波形图,很明显是曼彻斯顿编码
(五)曼彻斯顿编码解码
有关 曼彻斯顿编码 的详细内容,请参考这篇文章:
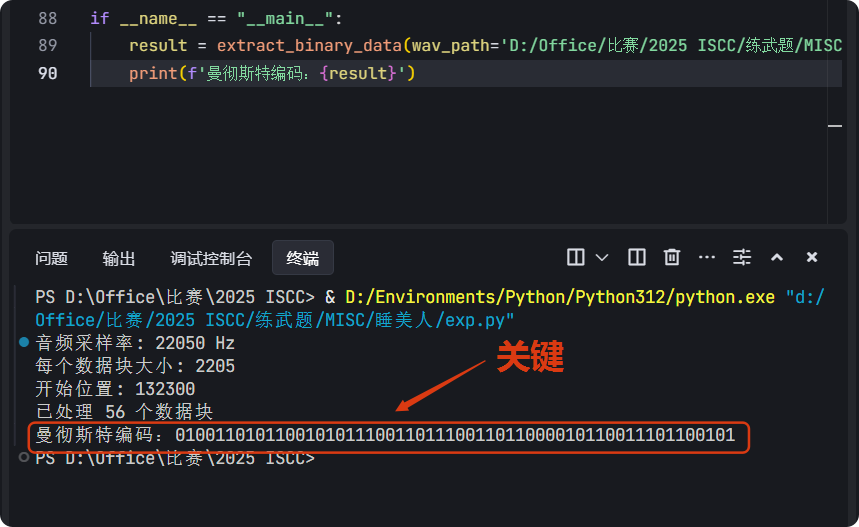
因为没有找到现成的工具,所以就只能自己写脚本了,得到如下一段信息:
01001101011001010111001101110011011000010110011101100101
1 | from scipy.io import wavfile |
(六)Flag解码
这里我们也不知道他对Flag进行了什么加密处理,丢给 随波逐流CTF编码工具 看看。
经过尝试后,最终我们发现Flag就是:2进制字符 英文:Message
Flag: ISCC{Message}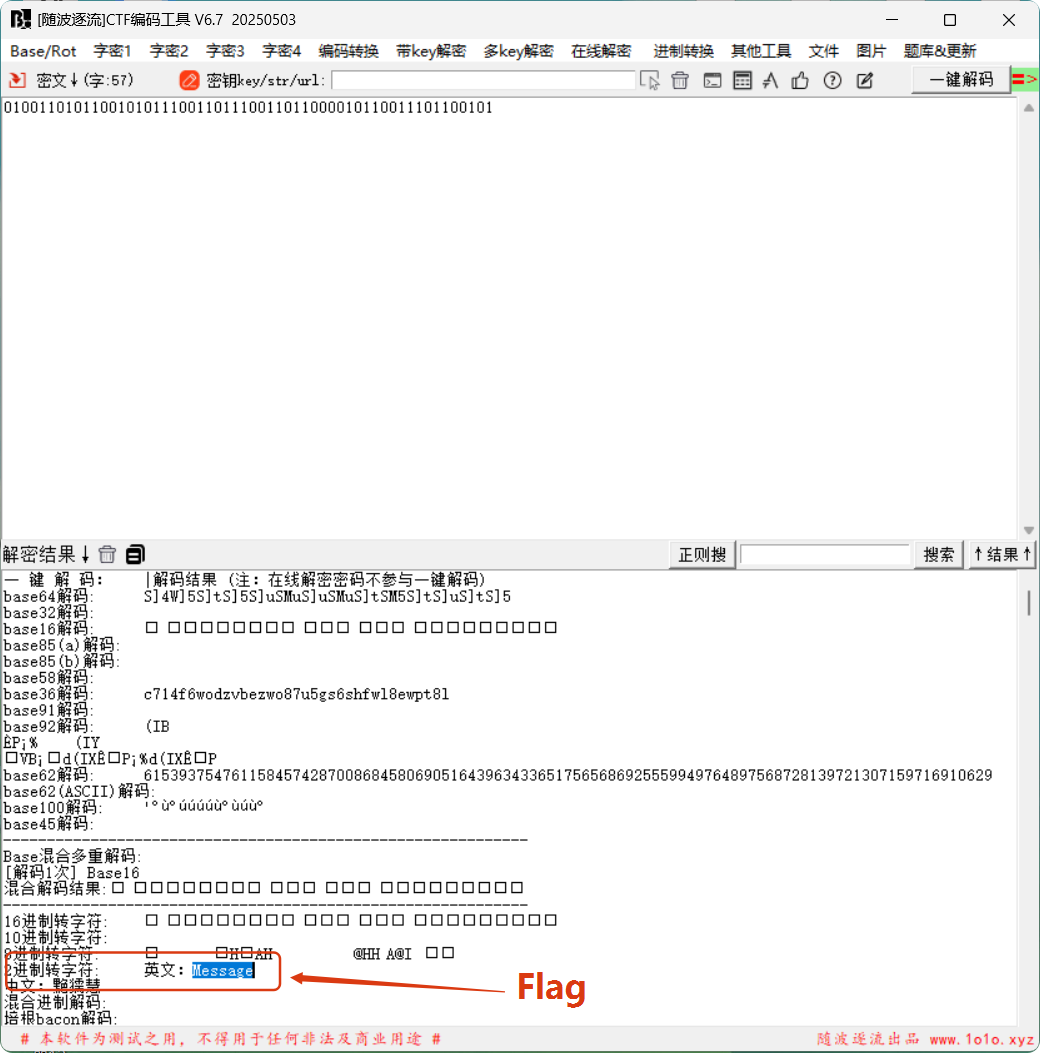
三、返校之路
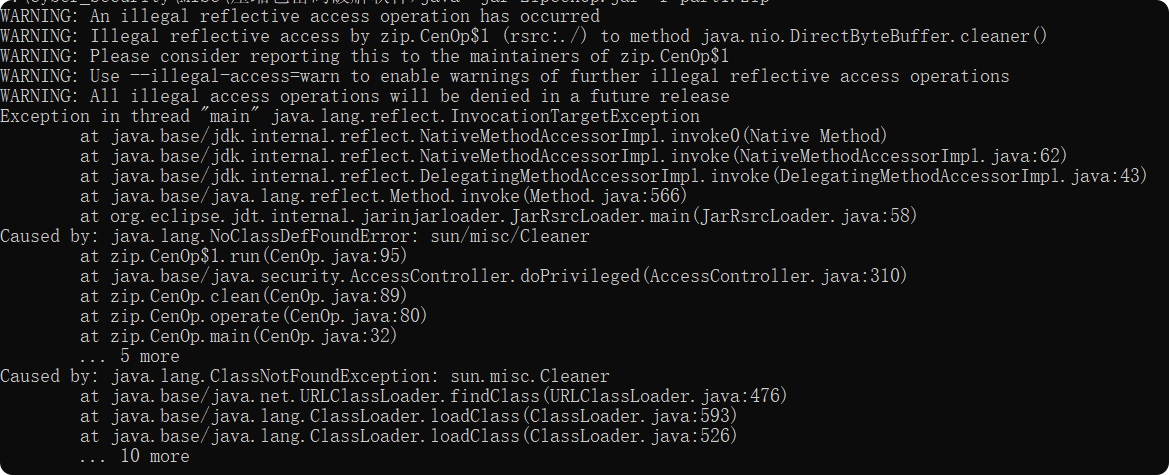
哎,拿到题目又是贱嗖嗖的 压缩包伪加密、加密压缩包掩码破解、图片隐写、信息提取
不过这道题,挺考验 信息提取能力 ,另外还有 耐心、细心
(一)压缩包伪加密处理
附件给中给了两个压缩包,一个是 part1.zip,一个是 part2_2.zip,先看看 part1.zip

工具:ZipCenOp 需要工具的,自取
提取码:fJ8V
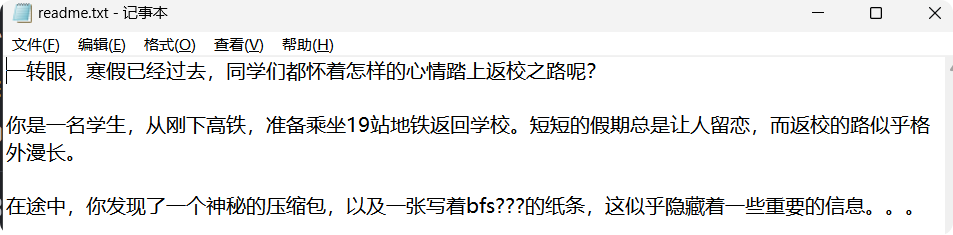
(二)获得掩码
part1.zip伪加密处理 去除密码后,直接解压,得到一个 readme.txt 文件,里面有一段掩码:bfs???,留着一定有用!
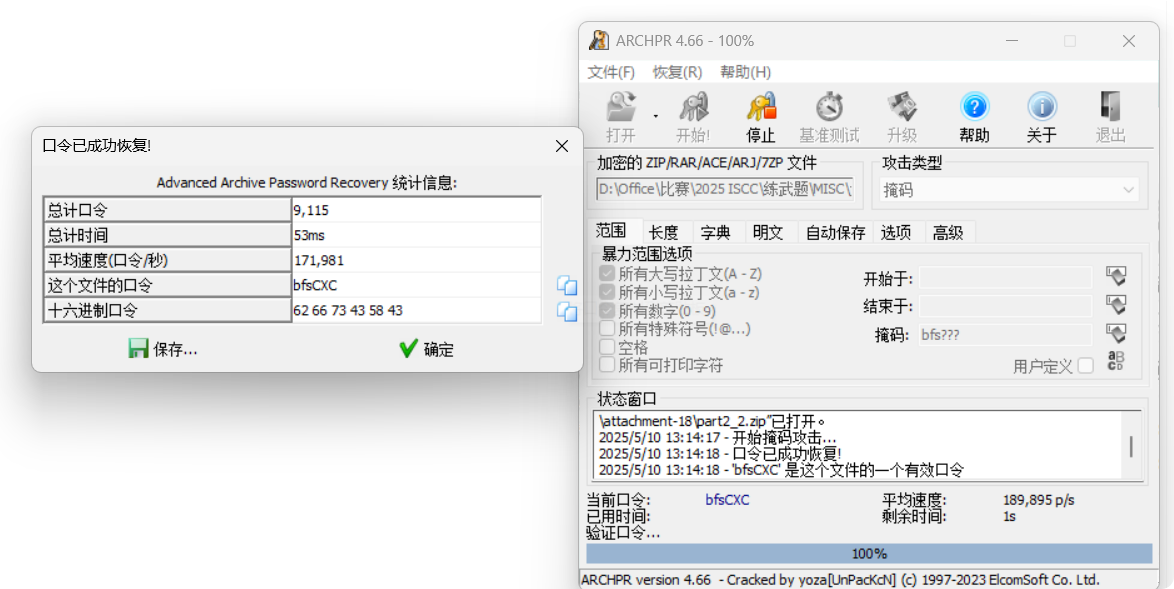
(三)掩码破解
part1.zip进行了伪加密处理,试试part2_2.zip,看看能不能打开,不出意外被加密了,这里掩码就派上用场了!
直接上工具 ARCHPR 得到了压缩包密码:bfsCXC
工具:ARCHPR
提取码:Lx2z
(四)返校路线分析
1.解压 part2_2.zip 后,我们得到了三张图片:
图片1【1.jpg】:朝阳站,3号线
![图片1:朝阳站,3号线]()
图片2【picture2.png】:地铁魏公村站,4号线
![图片2:地铁魏公村站,4号线]()
图片3【3.jpg】:北京地铁路线图
![图片3:北京地铁路线图]()


2.另外一点值得注意的是:
图片1和图片3命名都是阿拉伯数字1、2,但是图片2却是picture2
图片1和图片3都是jpg,但是图片3却是png
3.表面分析得出结论1:picture2.png 一定有问题
4.关键:路线分析
图片1:朝阳站,3号线 这是返校的起点
图片2:地铁魏公村站,4号线 这是返校的最后一程地铁线
图片3:北京地铁路线图 这是返校的路线图,我们就需要分析换乘的是坐哪号线:10号线
5.结论2——返校路线:3号线 -> 10号线 -> 4号线
返校路线拼接起来:3104
这就是 Flag第二部分:3104
(六)隐写分析
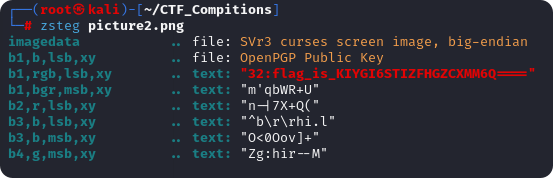
直接使用Kali自带的工具:zsteg 进行隐写分析,得到一段Base加密的字符串
KIYGI6STIZFHGZCXMM6Q====
(七)Base解密
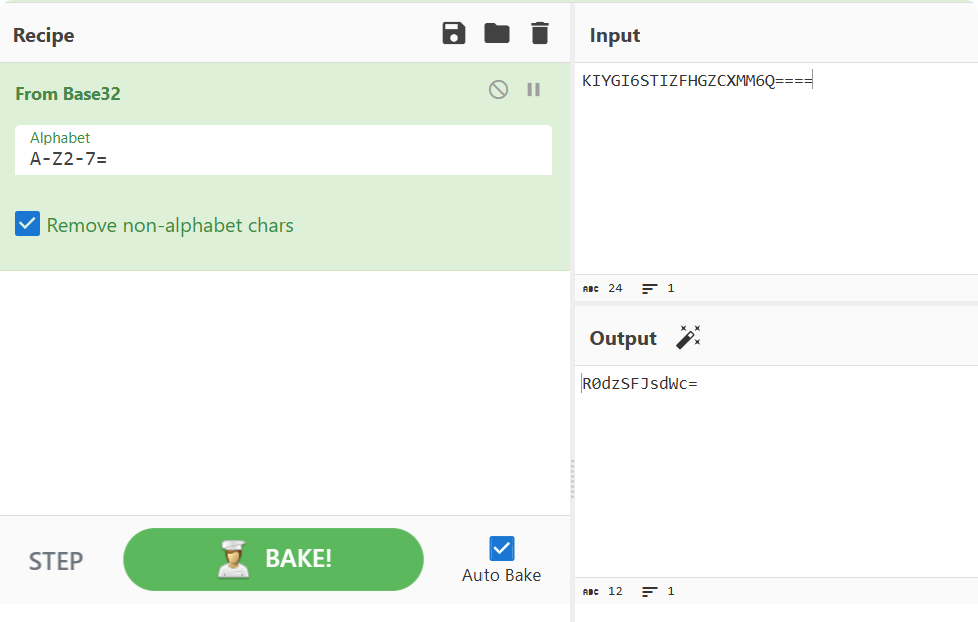
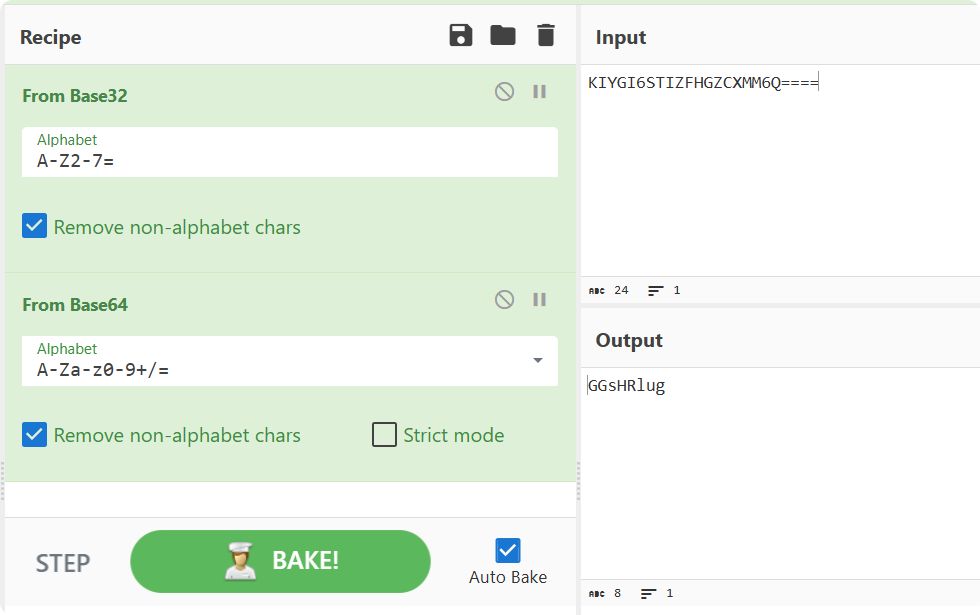
这里使用 CyberChef 进行Base解密,经过尝试后,是先进行 Base32 解密,然后再进行 Base64 解密。
- Base32 Decode:R0dzSFJsdWc=
- Base64 Decode:GGsHRlug
得到 Flag的第一部分:GGsHRlug
(八)Flag拼接
这个Flag也是当时试了好几次:
开始就只交了第二部分 ❌
然后将第二部分放在前边,第一部分放在后边 ❌
最后一次尝试,终于成功了!✅
- Flag第一部分:GGsHRlug
- Flag第二部分:3104
Flag: ISCC{GGsHRlug3104}
四、取证分析
(一)撬开Word文档
1.题目提示:“你想将压缩包中的一个文本的内容复制到word中再隐藏进一些内容”
2.总结关键信息:
- 压缩包
- word中隐藏
3.大胆尝试,将word文件后缀更改为zip,然后解压,我直接从凳子上弹射跳起来,Word被撬开了!发现关键文件Content_Types.xml
4.分析 [Content_Types].xml 文件,在注释中得到 关键字符串:qwiqpsabsqps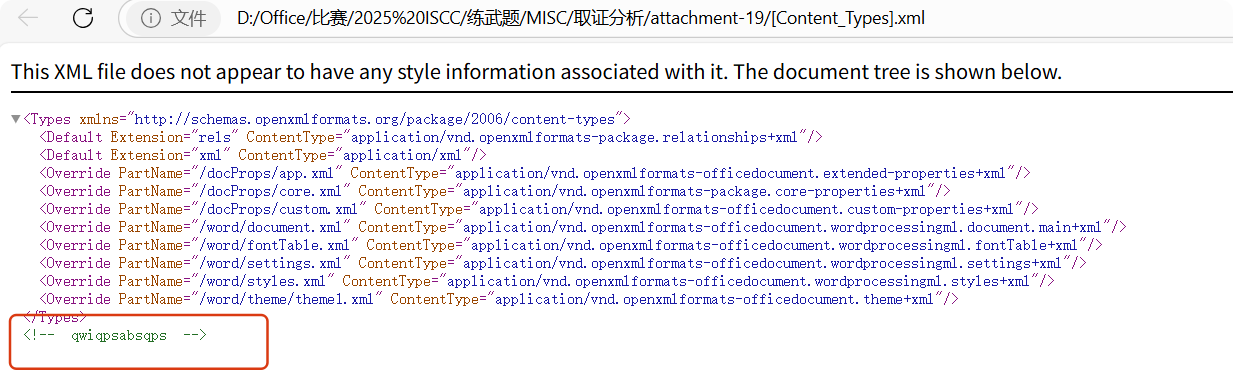
(二)Volatility进行取证分析
Volatility 是一款用于分析 Windows、Linux 和 macOS 内存转储文件(内存镜像)的工具,广泛应用于数字取证和安全分析领域。
详细安装教程请参考:
详细使用教程请参考:
1.查看镜像基本信息 —-> 【系统:Win7SP1x86_23418】
1 | python2 vol.py -f hint.vmem info |
2.查看进程信息 —-> 【关键进程:cmd.exe】
1 | python2 vol.py -f hint.vmem --profile=Win7SP1x86_23418 pslist |

3.对cmd进程提取命令历史记录 —-> 【对关键文件进行操作: hahaha.zip】
1 | python2 vol.py -f hint.vmem --profile=Win7SP1x86_23418 consoles |

4.提取hahaha.zip文件路径 —-> 【\Device\HarddiskVolume2\hahaha.Zip
】
1 | python2 vol.py -f hint.vmem --profile=Win7SP1x86_23418 filescan | grep 'hahaha.zip' |

5.导出hahaha.zip文件 —-> 【导出后文件:file.None.0x872a5b48.dat】
1 | python2 vol.py -f hint.vmem --profile=Win7SP1x86_23418 dumpfiles -Q 0x000000007e8a23c0 -D your_profiles_path |

6.Strings查看文件内容——>【关键文件:Alphabet.txt、hint.txt、readme.txt】
1 | strings file.None.0x872a5b48.dat |

7.尝试解压导出后的文件,提示需要密码【hahaha.zip文件被加密】
1 | unzip file.None.0x872a5b48.dat -d your_profiles_path |

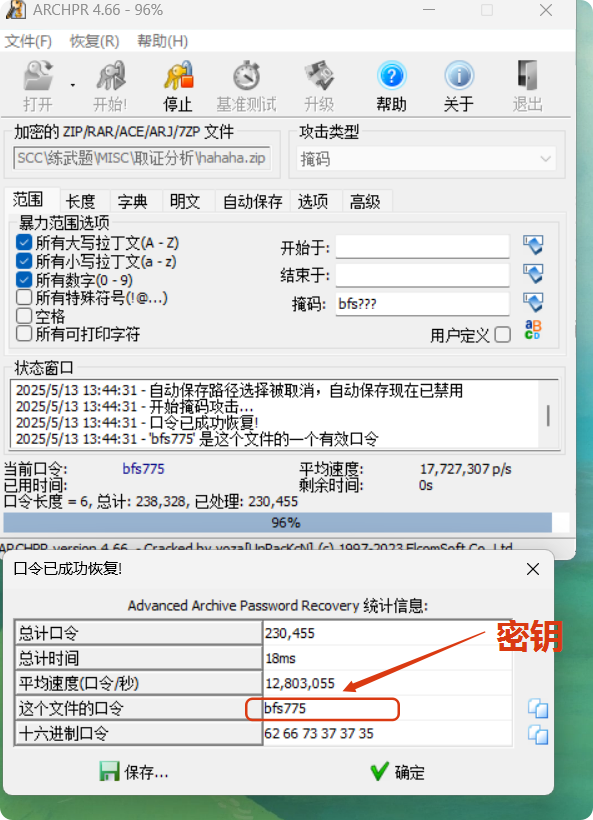
(三)掩码破解
将加密的文件,直接从kali中 Ctrl+C & Ctrl+V 放到 物理机中,这样操作起来更舒服~
掩码:bfs???
得到压缩包密码:bfs775
压缩包破解后,得到了我们期待已久的关键文件:
- Alphabet.txt
- hint.txt
- readme.txt
工具:ARCHPR
提取码:Lx2z
(四)关键文件分析
1.Alphabet.txt:杨辉三角数组坐标【(2,10) (4,8) (2,4) (3,4) (11,13) (2,11) (1,1) (10,26) (5,6) (5,9)】——>【维吉尼亚密钥关键】
2.Hint.txt:rxms{ husqzqdq oubtqd }
3.Readme.txt:“一段奇奇怪怪的字符”
(五)维吉尼亚密钥破解
这里,我们就只能自己写脚本破解了
最终的 维吉尼亚密钥:IICCNJAYER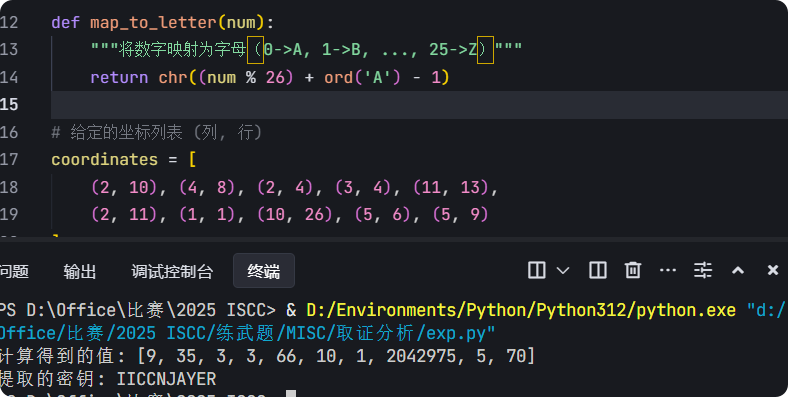
1 | import math |
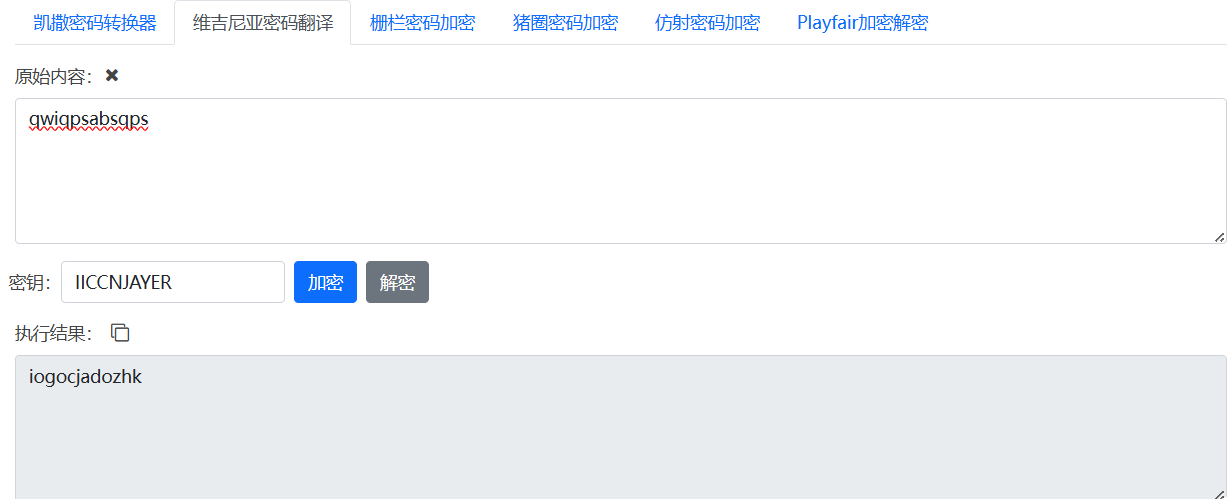
(六)维吉尼亚解密
密文:qwiqpsabsqps,这也就是我们从word嘴巴中撬出来的东西
维吉尼亚密钥:IICCNJAYER
随便找一个在线维吉尼亚解密网站,得到 iogocjadozhk
![维吉尼亚解密]()
(七)Flag
维吉尼亚解密得到的字符串,也就是最终的Flag
Flag: ISCC{iogocjadozhk}
- Thanks for your appreciation. / 感谢您的赞赏
 微信
微信 支付宝
支付宝








